【spreadsheet】Query関数の使い方と、他では見れない実例一覧
こんにちは、エドです。
スプレッドシート(SpreadSheet)を使っていて「スプレッドシートの情報を欲しいデータだけ抜き出してまとめれたらいいのに」と思ったことはありませんか?
もしくは「データの形式が決まっているけど見づらいから使いやすいように加工したい」「データを好きなように並び替えたい」「複数のデータを一つにまとめたい」等など・・・これらはすべて「Query関数」で実現できます。
ここではQuery関数の使い方と、何が便利なのか?そして具体的な便利な使い方について解説します!
ダレカンでは他の記事ではあえて解説しないような細かい部分まで解説します。できるだけ専門用語も使いません。初心者の方で「せっかく検索したのに解説が専門的で結局使い方がわからない・・・」という方も多いと思います。「ダレでもカンたんにわかる」がダレカンのテーマ。熟練者のかたは適宜読み飛ばしてね!
Query関数とは?
Query(クエリ)とは「問い合わせ」という意味。Query関数は「セルのデータから必要な情報だけを抽出する関数」のことです。
具体的にはセルの内容を「データベース」として扱い、そのデータに対してさまざまな条件を付けて抽出ができます。SQLという問い合わせ言語に詳しい方なら「スプレッドシートで簡易SQLが使えます」と言えばわかりやすいかもしれません。
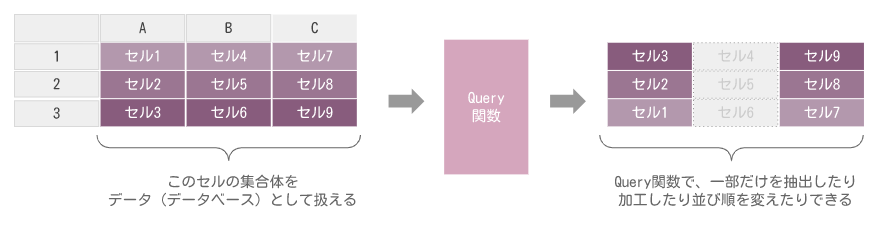
このQuery関数の便利なところは
・参照する元データを加工しないので、データが壊れない
・元データが変わったときは、即座に変更が反映される(更新する処理が不要)
・参照用元データと表示用の加工済みデータを別々に保持できるので、管理しやすいなどのメリットがあります。
Query関数の使い方
Query関数の基本書式はこちら
Query( [ データ範囲 ] , [ 抽出条件 ] , [ 見出し ] )
| 引数 | 説明 |
|---|---|
| データ範囲 | データを抽出する範囲。セル範囲の指定も可能 |
| 抽出条件 | 抽出クエリ。SQL文という文法で記載する |
| 見出し | 見出し行の行数。省略可。省略、もしくは-1を指定するとデータの中身に基づいて判定される。 |
Query関数で使用する引数
実際にQuery関数でデータを抽出する文法はコチラ。”種類”が”食べ物”のデータだけ抜き出しています。
=query(A3:B6,"SELECT A,B WHERE B='食べ物' ",1)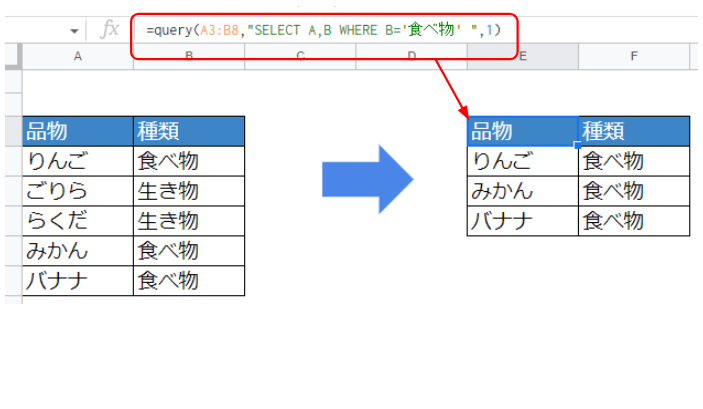
データ範囲
抽出したいデータ元の範囲をセルで指定します。
セル全体 → A:B
セル範囲指定 → A3:B6
といった指定をします。データ行数がどれくらいになるかわからない場合はセル全体を指定します。※不要なデータは抽出条件で省く
抽出条件
抽出する内容を記載します。基本的な書き方は「SQL」という構文に基づいていて様々な書き方ができますが、まずは
■抽出条件の指定:”where [列名]=’条件’ “
※条件部分に文字を書く場合はシングルコーテーション[‘]で囲む
■抽出列の指定 :”select [列名],[列名] “
※複数の列を抽出する場合はカンマ[,]で区切る
だけ覚えておくだけでも便利です。抽出条件は必ず”(ダブルコーテーション)で囲みます。
列名は大文字小文字を区別しますので、基本的に大文字で書きます。
どちらか一方だけを書くこともでき、両方同時に書くこともできます。順序があり、selectのほうを先に記述します。
見出し
見出し行の行数を数値で指定します。省略可。省略、もしくは-1を指定するとデータの中身に基づいて判定されます。予期せぬ表示にあることもあるので普段は見出しがある時は1、見出しがない場合は0を指定しましょう。
Query関数の基本的な使い方
指定した列だけを抽出
まずは基本。データから指定した列だけを抜き出します。
=query(A1:B6,"SELECT A",1)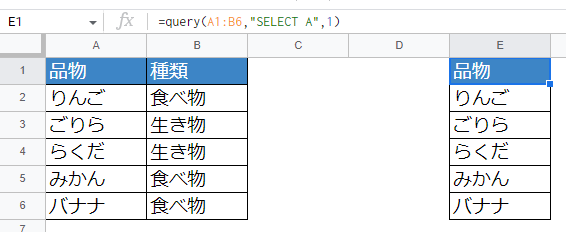
SELECTは「取得する列を指定する」命令です。列名はデータで指定した列をそのまま使います。
A1~B5のデータからA列を取得する場合は「A」と指定します。C1~F3のデータからD列を抜き出すなら「D」を指定します。
複数同時に指定することも可能です。複数指定する場合は、列名のあとにカンマ[,]を入れて区切ります。
=query(A1:B6,"SELECT A,B",1)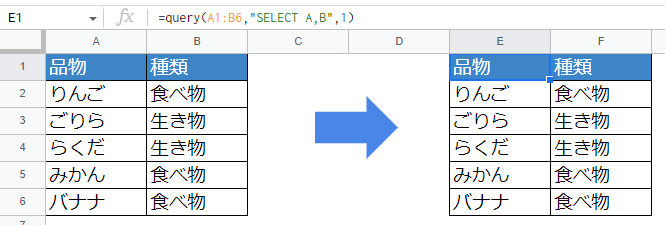
列を入れ替える
列を入れ替えることもできます。便利ですね。
=query(A1:B6,"select B,A ",1)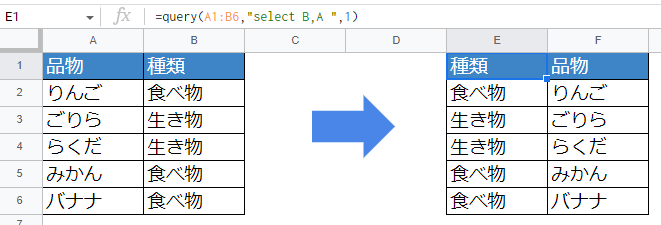
入替の方法は簡単で、selectの後に指定する列の順番を入れ替えるだけです。
抽出条件を設定する
データから抽出する条件を指定できます。
=query(A1:B6,"where B='食べ物' ",1)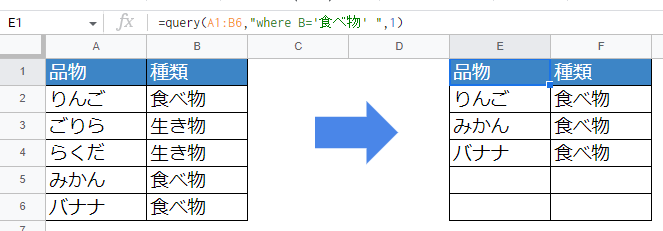
whereは「抽出条件を指定する」命令です。「”どこ”が”何の”とき」という指定の仕方で、列名の指定はselectと同じです。
例)B=’食べ物’ → B列の値が「食べ物」のデータだけ抽出
※抽出する条件に当てはまるかどうかは行全体で判断されます。Bが食べ物であるセルは「B2とB5とB6」だけですが、それに該当する同じ行のA列も抽出対象です
複数同時に設定することも可能です。複数指定する場合は条件が「○○かつ○○」ならAND、「○○もしくは○○」ならORと指定します。
複数の条件を指定する場合
B列が「食べ物」であり、かつA列が「りんご」を抽出する
=query(A1:B6,"where B='食べ物' AND A='りんご' ",1)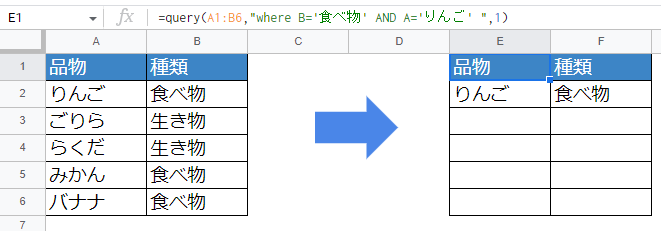
whereの条件をANDで区切って2つ指定しています。これらは「どちらの条件にも当てはまる場合」の指定です。
B列が「食べ物」である、もしくはA列が「ごりら」を抽出する
=query(A1:B6,"where B='食べ物' OR A='ごりら' ",1)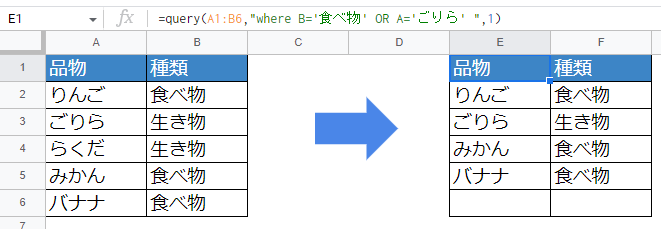
whereの条件をORで区切って2つ指定しています。これらは「どちらか一方の条件に当てはまる場合」の指定です。
条件に「セルの値」を使用する場合
抽出条件にH2セルの値を参照する。
=query(A1:B6,"where B='" & H2 & "'",1)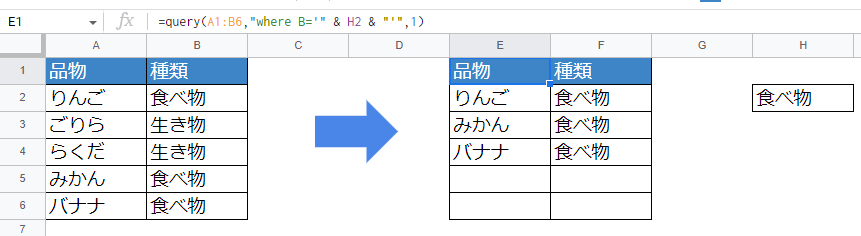
ずいぶん難しくなりました。Query関数の「抽出条件」はダブルコーテーション[“]で囲むのですが、これは抽出条件が文字列のためです。セルの値は文字ではない(H2という文字じゃなく、セル参照ですよね)ので、文字とセルを結合してあげないとエラーになってしまいます。
そのため ”抽出条件~” & [セルの参照] & “~抽出条件の続き”という記述の工夫が必要になります。
条件にイコール以外(大なり、小なり、以上、以下)を使うとき
=query(A:C,"where C > 300000 ",1)条件に「〇円以上」「〇円より大きい」などの条件を指定したい場合があります。
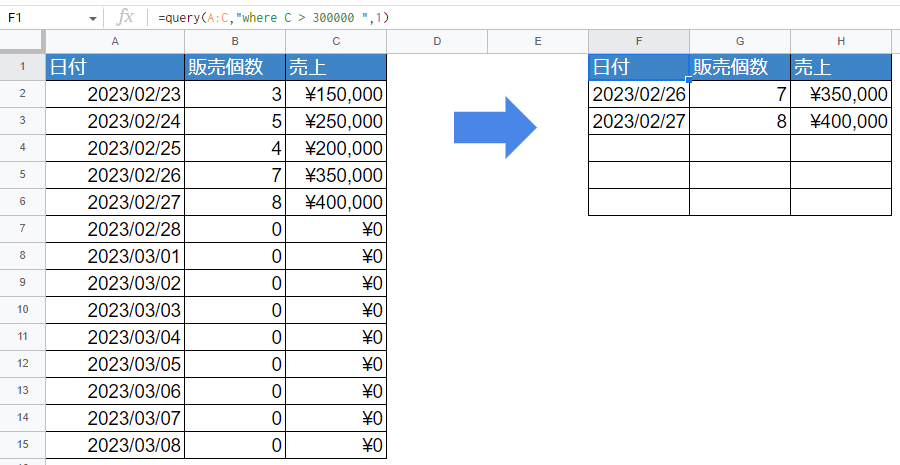
whereの後に「=」ではなく「<」や「>」を記述することも可能です。半角で。以上の場合は「>=」、以下の場合は「<=」と記述します。
並び順を変える
Query関数でデータを抽出する時に、並び順を変えることもできます。
=query(A:C,"select A,B,C where B >1 ORDER BY B",1)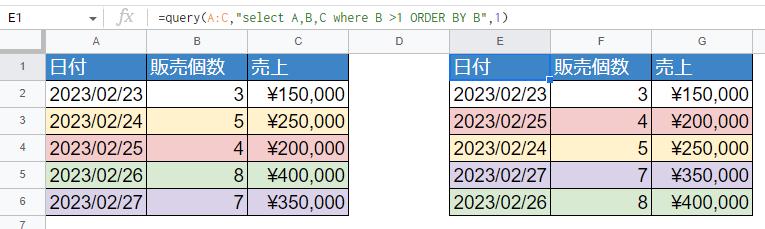
※行に色を付けました。並び順が変わっているとわかります
「ORDER BY」までは固定で、そのあとにスペースを一つ開けて列名を指定します。数字なら数字の小さい順、文字列なら文字の若い順(A-ZならAが先、あ-んならあが先)に並び順が変わっています。
並び順を変える(降順)
当然おおきい順(降順)に並び替えることもできます。
=query(A:C,"select A,B,C where B >1 ORDER BY B DESC",1)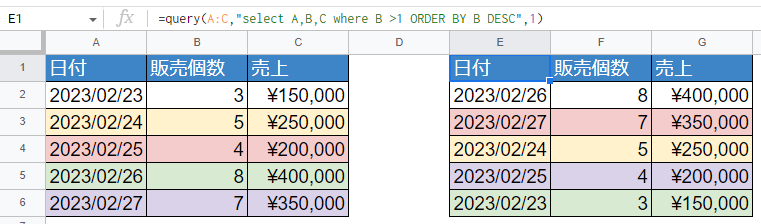
並び順を指定するORDER BYの最後に「DESC」と付けてあげるだけです。DESCが降順、ASCが昇順です。ASCは省略できます。
複数指定する場合
複数指定する場合は、ソートする列名をカンマで区切ります。DESCはそれぞれ付けます。これによって、Aは昇順でBは降順などといった指定ができるようになります。
=query(A:C,"select A,B,C where B >1 ORDER BY B DESC,A DESC",1)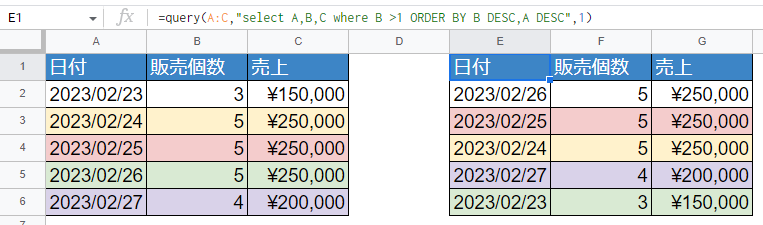
Query関数の便利な使い方
ここからはQuery関数の真骨頂。「様々な抽出ができます」と書きましたが、様々って何ができるの?という部分です。
列名を変更する
抽出した後、列名を変えたい時がありますよね。ない?変えれると便利ですよ!
=query(A1:B6,"where B='食べ物' Label B '分類' ",1)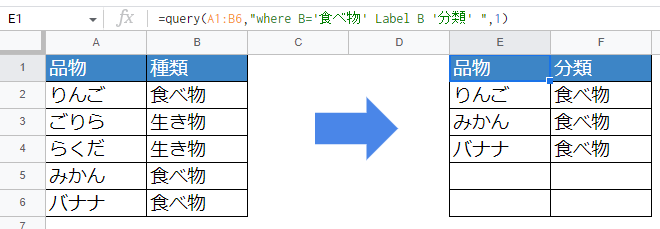
抽出前のB列名は「種類」でした。Query関数で抽出後は「分類」に列名が変わっています。labelという命令で列名を指定した後、半角スペースを入れて列名を記述します。列名はシングルコーテーション[‘]で囲みます。
これも記述の順番があり、selectやwhereの前には書けません。
複数の列名を変えたい
複数の列名を付けるときはカンマ[,]で区切ります。
=query(A1:B6,"where B='食べ物' Label A '食品', B '分類' ",1)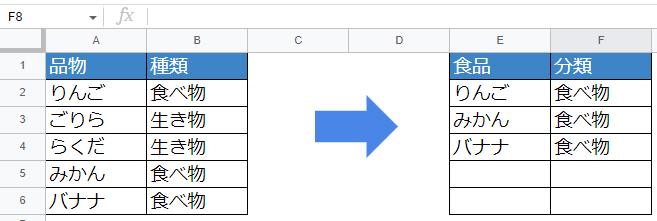
Query関数を複数合体させる(Query関数のネスト)
Query関数は、別々に抽出したデータを合体(マージ)させることもできます。
=query({query(A1:B6,"where B='食べ物'",1);query(A9:B13,"where B='食べ物'",0)})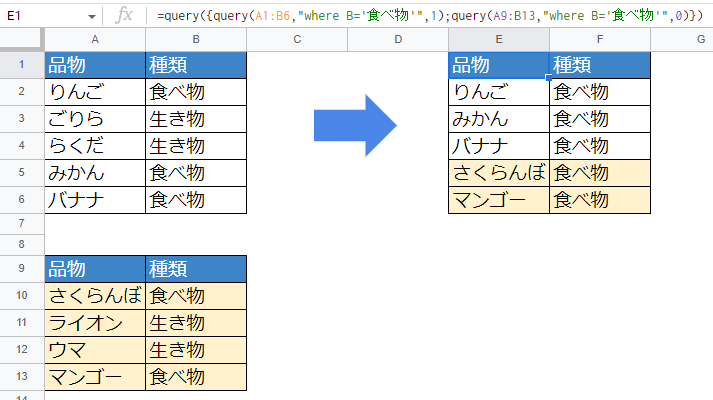
普段はあまり使わない方法なので、書き方はやや複雑ですね。シンプルにすると下のようになります。
= query( { [1つ目のQUERY関数] ; [2つ目のQUERY関数] } )
QUERY関数の中に{}を書いて、セミコロン[;]で区切る、ということです。実はこれ、3つ以上でもつなげることができます。
※注意として以下の条件に当てはまる場合しか設定できません
1.すべてのQuery関数の結果が「同じ列数」になること(1つめは2列返して、2つ目は3列だとエラー)
2.すべてのQuery関数にエラーがないこと(どちらかのQuery関数にエラーがあると全部エラー)
抽出条件に日付を指定したいとき
Queryで日付を扱うときはちょっとコツが必要です。
=query(A:C,"where A < date'2023-02-28' ",1)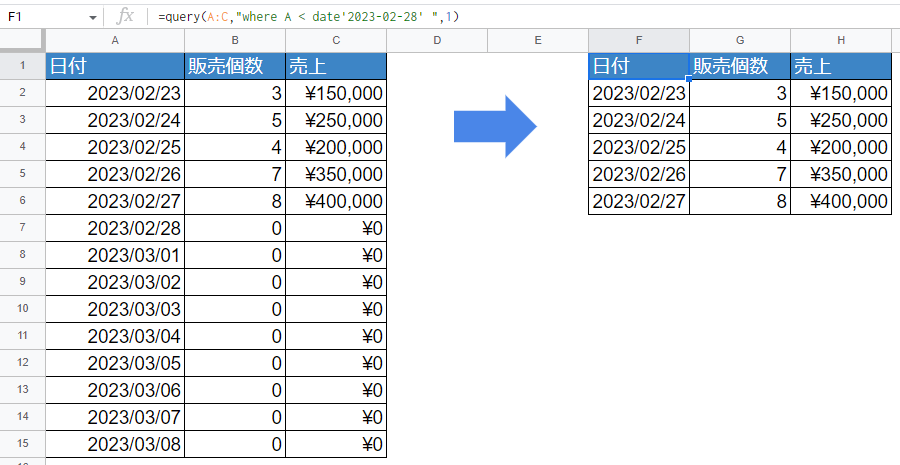
日付を指定する時は[date]を頭につけて、日付の形式を「yyyy-mm-dd」のようにハイフン[-]で区切ってあげる必要があります。日付も「文字としての日付形式」と「日付形式」があり、この抽出方法ができるのは「日付形式」の場合のみです。
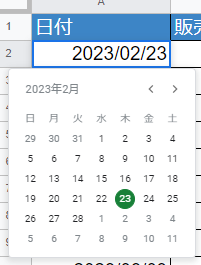
判別方法は色々ありますが、簡単なのは日付が入っているセルをダブルクリックしてカレンダーが出れば「日付形式」です。
元データの行数が決まっていない時
毎日売上データを記録する時、どんどんデータが自動的に増える表をデータとして使いたいとき、範囲が決まっていないけれどそのデータを加工して使いたい。そんな時ありますよね。
=query(A:C,"select A,B,C",1)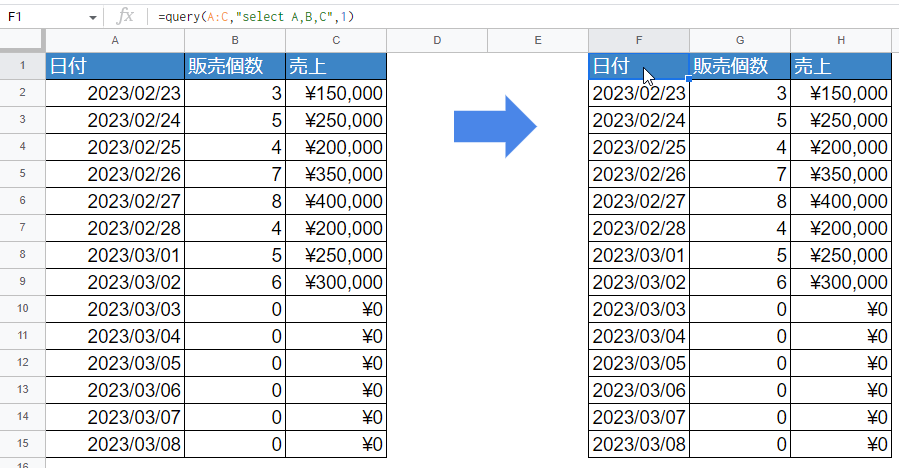
大事なのは、データ範囲部分の「A:C」部分。この指定の場合、範囲を決めないのでA列すべて~C列すべてという指定になります。もし上記のデータから「今日まで」のデータを取得したい、という場合はwhereに「今日まで」という条件を追加してあげます。
※今日が2/28日だとして、28日以前という指定方法
=query(A:C,"select A,B,C where A <= date'2023-02-28' ",1)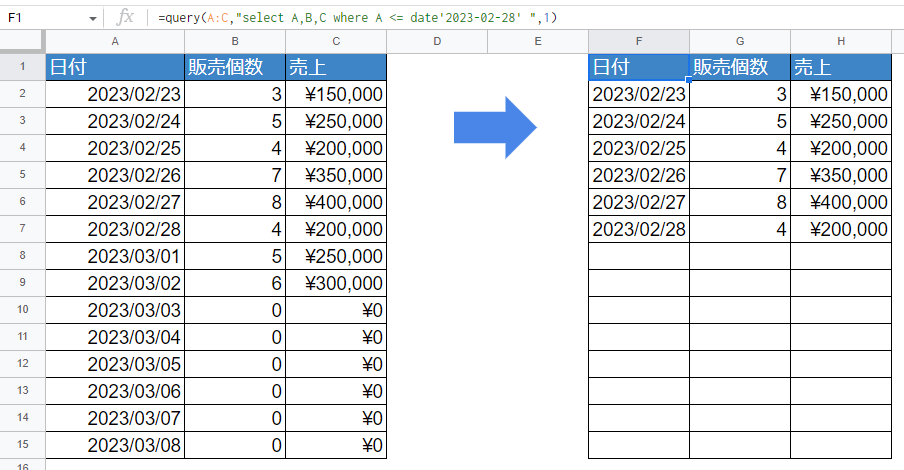
空白行を除外する
範囲を列全体で指定したとき、困ったことが起こる時があります。それは何もデータの入っていない空白行も取得されてしまうこと。
↓3月5日以前のデータを取得したいけど、販売個数のデータがない行は除外したい・・・
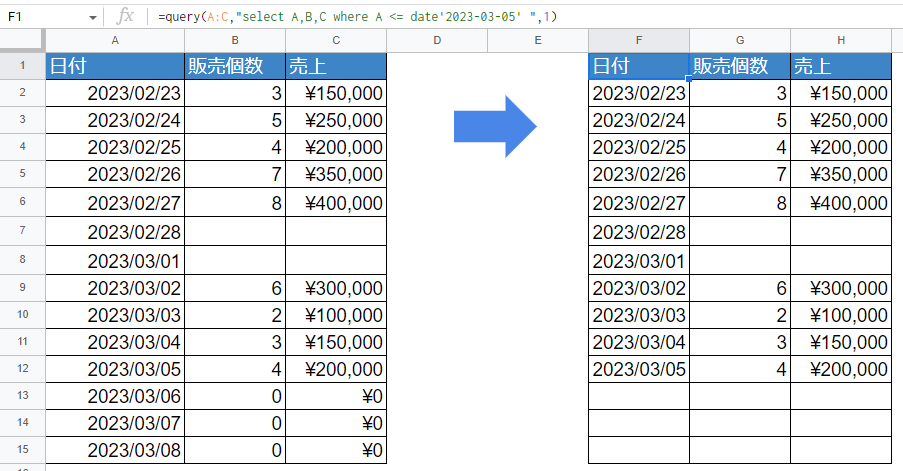
そんな時は「NULLのセル」を除外してあげます。NULLとは特殊な考え方で「データが何もない」ことを表す記号です。空白と似たような感じがしますよね。でも空白は「スペースが入っていても見た目上は空白」ですし、目には見えないけれど「改行を表す文字」が含まれていることもあります。それとは違い「本当に何もデータがない」ことを示すものがNULLだと考えていただければOKです。
つまりQuery関数で「データがNULLのものを除外」と指定してあげればよいのですがNULLは指定の仕方がちょっと特殊です。
"WHERE A IS NOT NULL"といった書き方が必要です。上記は「A列がNULLではない」という意味になります。前置きが長くなりましたが、先ほどの表をNULLを除外する時の書き方はこのように指定します。
=query(A:C,"select A,B,C where A <= date'2023-03-05' AND B IS NOT NULL",1)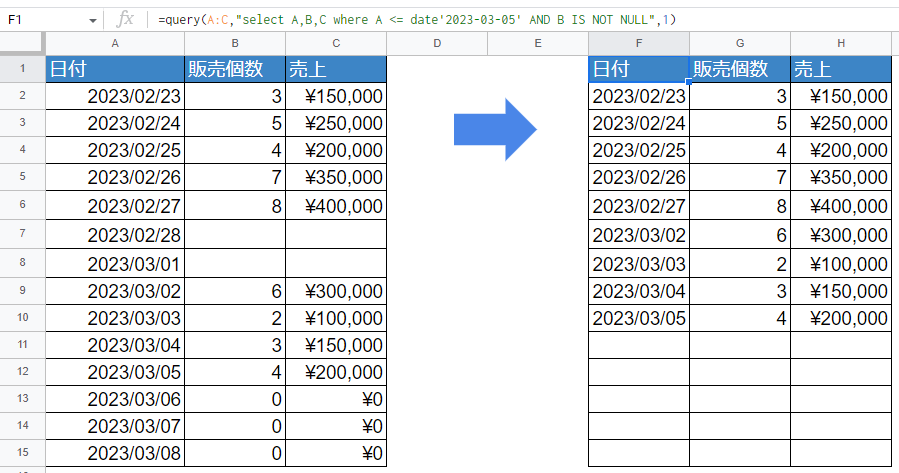
マニア向け
ここからはマニアックな内容やプログラム知識がある人に向けた解説です。詳しく解説はしないので実例集として参考にしてみてください。
結果のグルーピング
SQLでいうところのGroupByが使用できます。GroupByしたときのSelectはSQL文と同じく集計関数を挟む必要があるので注意。
=query(A:D,"select MIN(A),B,SUM(C),SUM(D) where A IS NOT NULL Group by B",1)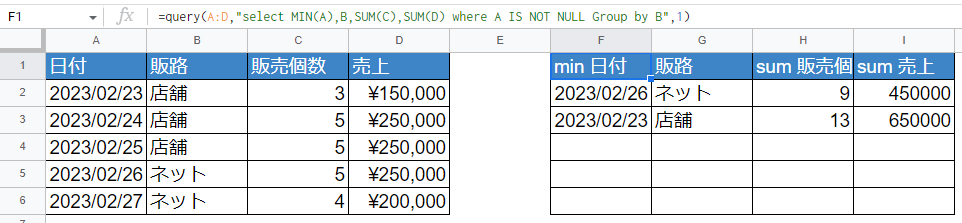
IS NOT NULLを入れているのはA:Dで列全体が対象のため空白行のグルーピング行も作られてしまうため。
Query関数のネスト(列のマージ)
先の解説で複数のQuery関数を使って行のマージができると解説しましたが、列のマージも可能です。
=QUERY({QUERY(A1:C6,"SELECT A,B,C",1),QUERY(E1:G6,"SELECT G",1)})
複数のQuery結果で抽出する行数は、すべて同じ行数でないとエラーになります。(Query1が3行でQuery2が2行だとエラー)
HAVING同等の処理を実現(Query関数のネストで実現)
マニアならGroupByがあるならHAVINGを使いたくなるはず。でもQuery関数にHAVING句はありません。そこで疑似HAVINGとしてQuery関数をネストします。
=query(query(A:D,"select MIN(A),B,SUM(C),SUM(D) where A IS NOT NULL Group by B ",1),"where Col2='店舗'")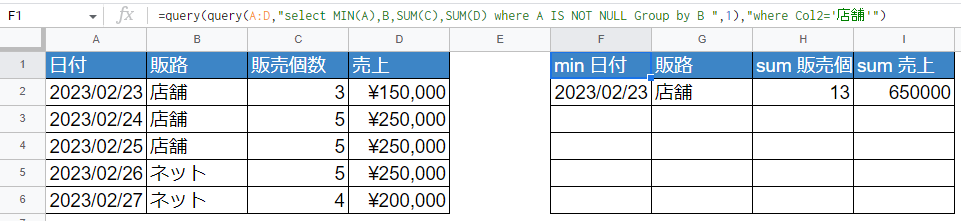
後半の「=query(query(A:D,”select MIN(A),B,SUM(C),SUM(D) where A IS NOT NULL Group by B “,1),“where Col2=’店舗'”)」部分に注目。列名を指定するのではなく「Col2」と指定しています。
これはネスト元のQuery関数から返ってくる列が、列名ではなく「Col1,Col2,Col3…」のように定義されているため。大文字小文字まで含めて正確に指定しないとエラーになります。(ここを解説しているサイトが少なかった・・・)
Col1 → ○
col1 → エラー
Col1 → エラー(1が全角)
さいごに
いかがだったでしょうか。とても便利な関数だったことはわかりましたね。Query関数は使い方が決まっている関数とは違ってアイディア次第では無限の可能性を秘めています。
私は本業がSEOコンサルタントなのですが、日々のお客様のデータをまとめたり、わかりやすく見てもらうためにフル活用しています!これとArrayformula関数は組み合わせると専門ツールを凌駕するほど優良です。
そして、実はここで解説したものは「ダレカン読者」用に簡易的に解説しています。
深く知りたい方は専門サイトのほうで確認するとよいかと思います。(説明を投げてるわけじゃないです笑)
またなにかいいテーマが合ったら別のものも詳しく解説していきます!

